The 'Inference Tax' Just Dropped: Why TurboQuant Is a Game Changer
We’ve spent years obsessing over model weights, but the real bottleneck for scaling LLMs has always been the KV Cache — the “short-term memory” that eats up VRAM and slows down long-context conversations.
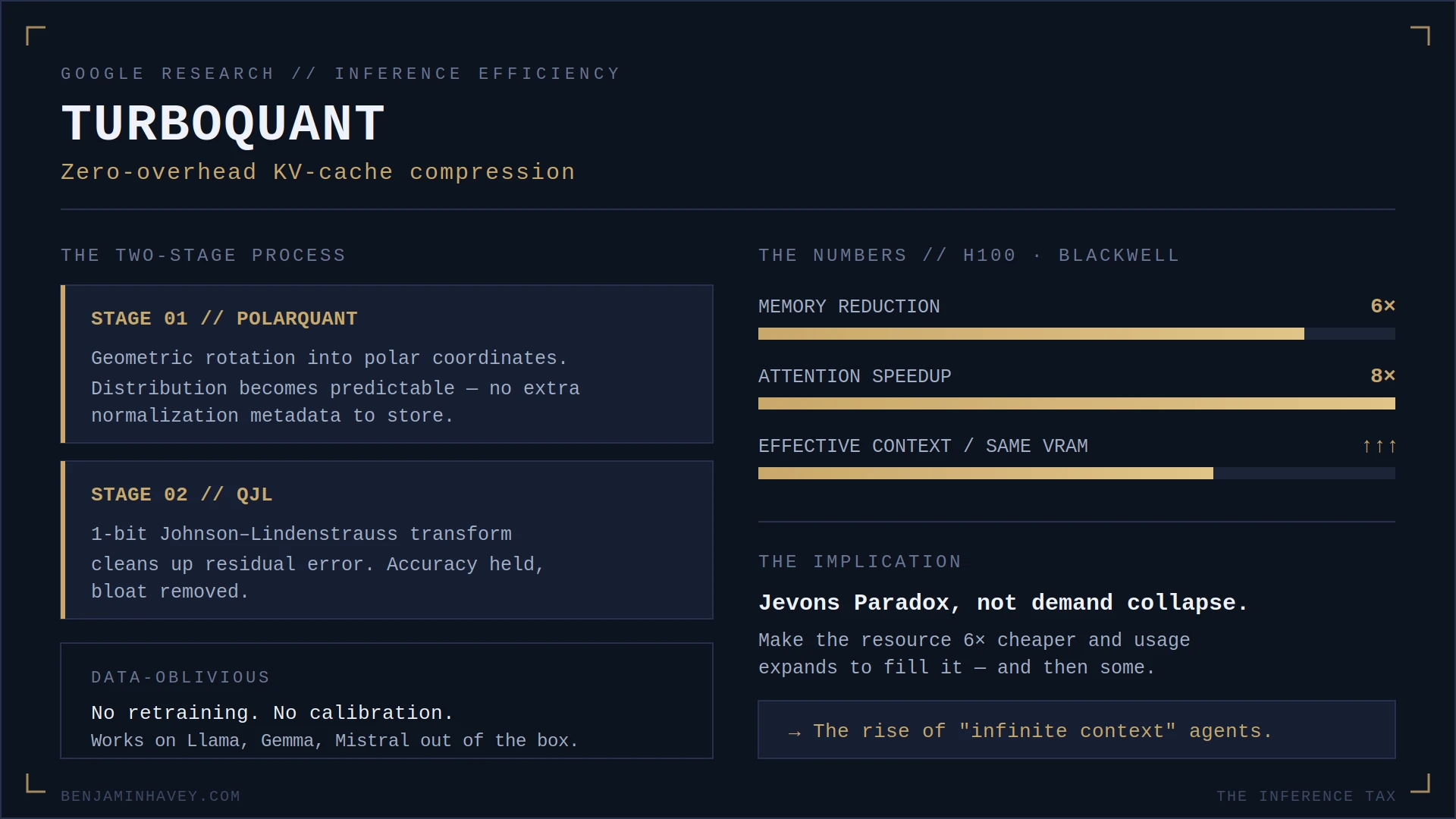
Google Research just changed the math with TurboQuant.
The technical “magic”
Most quantization methods come with a “metadata tax” (quantization constants) that eats into your savings. TurboQuant achieves zero-overhead compression through a two-stage process:
- PolarQuant: It uses geometric rotation to move data into polar coordinates, making the distribution so predictable you don’t need to store extra “normalization” data.
- QJL (Quantized Johnson-Lindenstrauss): A 1-bit transform that cleans up any remaining errors, ensuring the model stays accurate without the bloat.
The numbers (on NVIDIA H100 / Blackwell)
- 6x memory reduction: Fit massive context windows into the same hardware.
- 8x speedup: Faster attention means near-instant responses for complex prompts.
- Data-oblivious: No retraining. No calibration. It just works on Llama, Gemma, or Mistral out of the box.
The business implications
While some fear this will lower demand for HBM (High Bandwidth Memory), I’m betting on Jevons Paradox. When you make a resource 6x cheaper, people don’t use less of it — they find 10x more ways to use it.
We are about to see the rise of “Infinite Context” agents — AI that can remember weeks of project history or entire codebases without breaking the bank or hallucinating.
The “Memory Wall” isn’t gone, but it just got a lot shorter.